
Chances are pretty good that you’ve seen at least one of the many articles and tweets flying around lately about Web Components and Frameworks. For the past week I’ve watched as all sorts of arguments have been made by friends of mine on both sides and wanted to weigh in and share some thoughts, but my life hasn’t been cooperating. Finally, I have a moment so I tried to put down some thoughts that have been banging around in my head… No guarantee they are coherent and I’m out of time, so here they are….
A lot of developers (by far the vast majority) don’t work for browser vendors, they aren’t involved in building frameworks or standards development. They don’t have the time to spend a few years considering all of the gory little details and discussions that got us to where we are today. A lot of us stay in the loop by looking to and take queues from a comparatively small number of people who do and boil it down for us. We all have to do this with at least some things. Then, we then further categorize into “good” and “bad” piles mentally, and we use that to determine what’s worth spending time on or what will be a waste. Right now, for most people, it’s probably a little overwhelming. Which pile do Web Components belong in? Are they going to be Shangri La or a real shit show?
The answer is: No. Neither. A little of both at times. I’m sorry if that sounds wishy-washy but real life is like that. It’s full of grays. We move forward in fits and starts. We frequently can’t even predict what people will do with things until they get them – I’ve written about all of this a lot. Reality is messy. Getting agreement is hard. Truth is often subtler than we imagine and non-binary.
Let me explain what I mean though because without more, that’s kind of a non-answer…
Web Components are super cool, and also – believe it or not – imperfect. I think that they’re a fundamental step toward us getting much better at a lot of things, and I think we’re kidding ourselves if we think it’s not going to be bumpy for a while while we sort some things out. I believe that we can make them work with very popular frameworks and I also believe that they are not ideally suited to them today for a number of reasons and that people may choose not to use them. This creates challenges that I think we are not articulating well and… that actually might matter.
Web Components or Custom Elements?
Since I’m talking about articulating to developers… We’re not always clear on this. Sometimes we’re even conflating Web Components with Polymer. We’re doing better than we were in 2013, but we’ve got to do better still. Polymer isn’t Web Components in the way that birds aren’t ducks. Polymer is conceptually built around Web Components, but it’s a library. Because it is a library created by Google and it includes polyfills and prollyfills and because these are not always historically clearly labeled, that’s gotten a little confusing sometimes. Occasionally, that’s caused bad feelings. Use Polymer, React, Angular or Ember. They’re all good, I’m not trying to pick on one. Just be aware what’s what and what isn’t. Your mileage may vary.
So, in an effort to be clear – in this piece I when I say “Web Components” I am talking about Custom Elements and Shadow DOM as those are the two pieces that are near shipping.
Can/should you use the current incarnation of Web Components with all of the popular frameworks?
Yes, probably you can… Sort of.
Believe it or not, I think this is where most of the trouble lies. “Can you” isn’t the question to ask. “Should you” or “Will People” are the questions. One group says “resoundingly yes you should because it is native and therefore is most widely usable.” Another counters “potentially you can, but you really might not want to with a framework because it won’t be as convenient as you might think. A lot of components will either not work or will require wrappers/adapters in practice”. “Can” has a definite answer and, I’m pretty sure the answer is “yes” because we can make just about anything work if we try hard enough (see: the entire Web).
That’s where “should you” comes in and I’m afraid that the answer there doesn’t seem so cut and dry – and that “Will People” is kind of up in the air. Why? Because “can you” isn’t the only variable. You’ve probably had experiences where it gets pretty hard and you think “is this really worth it?” I’ll tell you about one of those I had below that makes me sensitive to this one. I’m happy to be shown “it’s worth it” in actual practice and “people will (more than once)” in the real world, but my own experiences thusfar don’t entirely bear that out. I’ll also explain why I’m ok with that.
It’s a pickle. But it’s a pickle like “should you do x” and we have a lot of those.
Will people use Web Components with their framework?
Yes, or at least they will try if a whole bunch of people are all telling them that for sure this should work and that’s part of what people are worried about. I’m not sure this is being well articulated but the worry that some have is: It’s not going to be the walk in the park that they imagine and that’s that’s going to turn people off to Web Components. Even framework people think that would be a shame because we all agree that Web Components are a great idea that we absolutely want. Web developers have been disappointed and frustrated a few times already with challenges in the morphing of Web Components as we struggled to get consensus. Regardless of reasons or blame, that seems true and we probably can’t afford a lot more of that.
So, should we go back to the drawing board and re-think Web Components from the ground up?
Hellz No! But, believe it or not, I don’t actually think anyone really meant to imply this literally regardless of what they might have said in 140 characters one day after lunch.
Why not?
Because they’re a good step forward and not shipping something fits just as neatly under the “we probably can’t afford a lot more of that” heading.
For those who might not be aware, “Web Components” is actually a cold reboot of many previously failed attempts to do many of the same things – HTC, XUL, XAML, FLEX and XBL were all trying to do the same. These efforts were restarted, to the best of my recollection around 2009 or 2010 under the banner “Web Components” – but you can track the general idea of “custom elements” (lowercase because they were more like “Web Components”) in some fashion back, practically as far as the Web itself. In all that time, we have never been so close. Why? Because the problem is hard. Because new things come along and give us pause. Because consensus is hard. Even just between those who actually make a browser it is, in a word: fucking hard. Standards are like this Weird Al Song . On anything that asks for the ability for authors to be able to mint elements and define them, doubly so.
It’s not the end of the game but we can’t move on further until we beat this level.
So what should we do?
Just be realistic I think. We move forward in steps. If we are pitching an all-singing, all-dancing, no challenges to be found future, that’s probably not realistic. A de-facto implementation that will be used everywhere regardless of framework, might be over-selling a vision until we actually see it broadly happen. Sure, it might be possible, but possible isn’t the only variable. It’s also entirely likely that even if someone posted such a thing, even one with an adapter for Ember or React, or even Polymer of a very popular custom element with “Web Components Underneath” that within a few days someone will say “yeah, but that’s inefficient”. It’s pretty easy for them to make a derivative component in their framework that does the same thing but cheaper, and it’s very likely that many people with that framework will gravitate toward the “more efficient for their framework version.” I’m not sure. We’ll see. That’s all I’m saying. That and…
Meh.
Meh?
Yeah, meh. I’m ok with that for now. We’re not there yet, but we’ll figure it out as long as we work together. I know that might sound a little disappointing if you were hoping for total Nirvana – but it’s hella better than what we had a few years back. Declarative solutions are very easy to use and thank goodness we all agree on that much, even to the basic point of how we express them. In fact, all of the major frameworks have a solution that looks a lot like Custom Elements. Here’s some markup, is it an Ember component or a Custom Element? You can’t tell.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| <div> | |
| <common-button id="btn">Statu</common-button> | |
| <common-badge icon="favorite" for="btn" label="favorite icon"></common-badge> | |
| </div> |
Yes, it means there might be N implementations of the same thing instead of the one true implementation — and yes that kinda sucks. But… meh.
We have armies of developers who are probably willing to port a popular custom element to their framework of choice until we sort this out. Within my own company we have some things implemented twice – once as a Custom Element and once as an Angular directive. It didn’t start that way, it wound up that way because that turned out to be easier and more efficient to say to Angular “Ok – you be you”. I fought it until I could fight no more. Now that we did it, it’s not the end of the world. The folks who write markup still don’t need to learn something new moving from frameworkless pages to Angular pages. Their knowledge is portable. That’s not as amazing as I’d originally hoped, but in practice, it’s actually been pretty damned good. And I’ll take it over all of the N-solution, very complex alternatives we had before any day.
I believe we will get to the day when that isn’t necessary, but – if someone says “that day might not be today” I don’t think they’re just being difficult. I’m super happy to be shown – in reality – that this isn’t likely, but there only time will tell. Dueling speculations won’t tell us, only real experience will.
The mere fact that we can mint tags and easily transfer understanding between all of these is, in itself, a pretty significant leap in my opinion. That it allows us to begin the process of developers helping to establish the “slang” and further wrestles away creative powers from being the sole domain of browser vendors and for standards to play the role of dictionary editors is, in and of itself, pretty significant. We should throw this in the win column regardless of any of that other stuff.
What next? Are we resigned to this forever?
Nah, I don’t think so. We should manage expectations for now, but React, Ember and Angular all have some really interesting observations about declarative serialization and how we express things and why that’s a challenge for Web Components within their frameworks. We should listen. We should gain some experience. We should also write the hell out of some Web Components and see what we can do. Given new abilities I can’t wait to see what developers come up with. New capabilities inevitably breed new ideas and solutions that it’s nearly impossible to imagine until it happens.
Will it be as pretty as it might be if we started over? Probably not, but, I think it’ll actually get done this way. If we make some progress, we inch the impossible destination ever closer.













 Imagine then, that we could go back in time – low level features exposed and the ability to mint custom elements. Imagine, if you can, that this was part of the Web from Day One. It’s a big ask of the imagination, I realize, but it requires no more suspension of belief than time travel or a genetic mutation that somehow grants its possessor control over the weather, and we find that entertaining, so try to follow along…
Imagine then, that we could go back in time – low level features exposed and the ability to mint custom elements. Imagine, if you can, that this was part of the Web from Day One. It’s a big ask of the imagination, I realize, but it requires no more suspension of belief than time travel or a genetic mutation that somehow grants its possessor control over the weather, and we find that entertaining, so try to follow along…


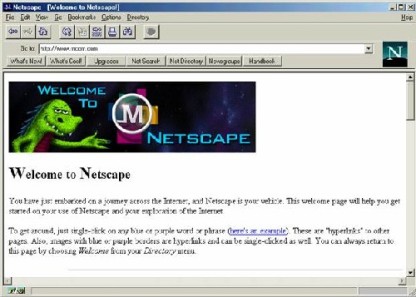 In March 1994, Silicon Graphics, Inc. (SGI) founder Jim Clark begins working on a business venture with Mosaic creator Marc Andreessen. They’ll hire up a lot of talent from both SGI and NCSA and they’re working on some server products and, more importantly a commercial browser built to kill Mosaic. Initially it is called “MCOM” (Mosaic Communications). Internally, the browser project is called “Mozilla” (a name given to it by another co-founder, Jamie Zawinski, who would go on to write much of the Unix version of their 1.0 browser) or “Mosaic-killer”. As you might imagine, the MCOM name was a problem and so “Netscape” was born. Very early Netscape website (while still in the mcom.com domain) even featured a “Mozilla” character originally created by employee Dave Titus.
In March 1994, Silicon Graphics, Inc. (SGI) founder Jim Clark begins working on a business venture with Mosaic creator Marc Andreessen. They’ll hire up a lot of talent from both SGI and NCSA and they’re working on some server products and, more importantly a commercial browser built to kill Mosaic. Initially it is called “MCOM” (Mosaic Communications). Internally, the browser project is called “Mozilla” (a name given to it by another co-founder, Jamie Zawinski, who would go on to write much of the Unix version of their 1.0 browser) or “Mosaic-killer”. As you might imagine, the MCOM name was a problem and so “Netscape” was born. Very early Netscape website (while still in the mcom.com domain) even featured a “Mozilla” character originally created by employee Dave Titus.
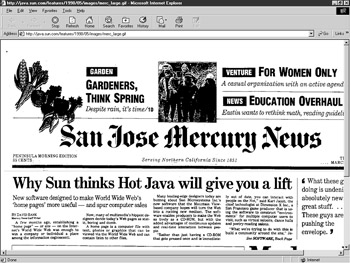 By March 1995 Sun was giving some demos to people outside and “Java” was starting to make news. The San Jose Mercury News ran a front-page piece entitled “
By March 1995 Sun was giving some demos to people outside and “Java” was starting to make news. The San Jose Mercury News ran a front-page piece entitled “

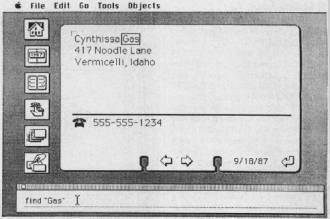

 Another two years later people were really starting to take notice of “HyperText” (and beginning to get a little over-generalized with the term – frequently this was really becoming “HyperMedia”). In 1987, an application called “
Another two years later people were really starting to take notice of “HyperText” (and beginning to get a little over-generalized with the term – frequently this was really becoming “HyperMedia”). In 1987, an application called “






